Some apps can afford to have no concurrency. The rest are the reason why books on concurrency exist1.
I have two examples from my recent experience. Pulse has practically no concurrency, no parallelism, and does everything on the main thread. On the other end of the spectrum is Nuke that has to be massively concurrent, parallel, and thread-safe.
Nuke is often used during scrolling, so it has to be fast and never add unnecessary contention to the main thread. This is why Nuke does nothing on the main thread. At the same time, it requires very few context switches. And that’s the key to its performance (among numerous other performance-related features).
There isn’t much to say about Pulse: you can’t have threading issues if you don’t have threading. But when you need it, concurrency is notoriously hard to get right. So what do you do?
{kind=link}
Overview #
If you group the primary components in Nuke based on the concurrency primitives, you’ll end up with roughly four groups. There isn’t one pattern that dominates. Each situation requires a unique approach.
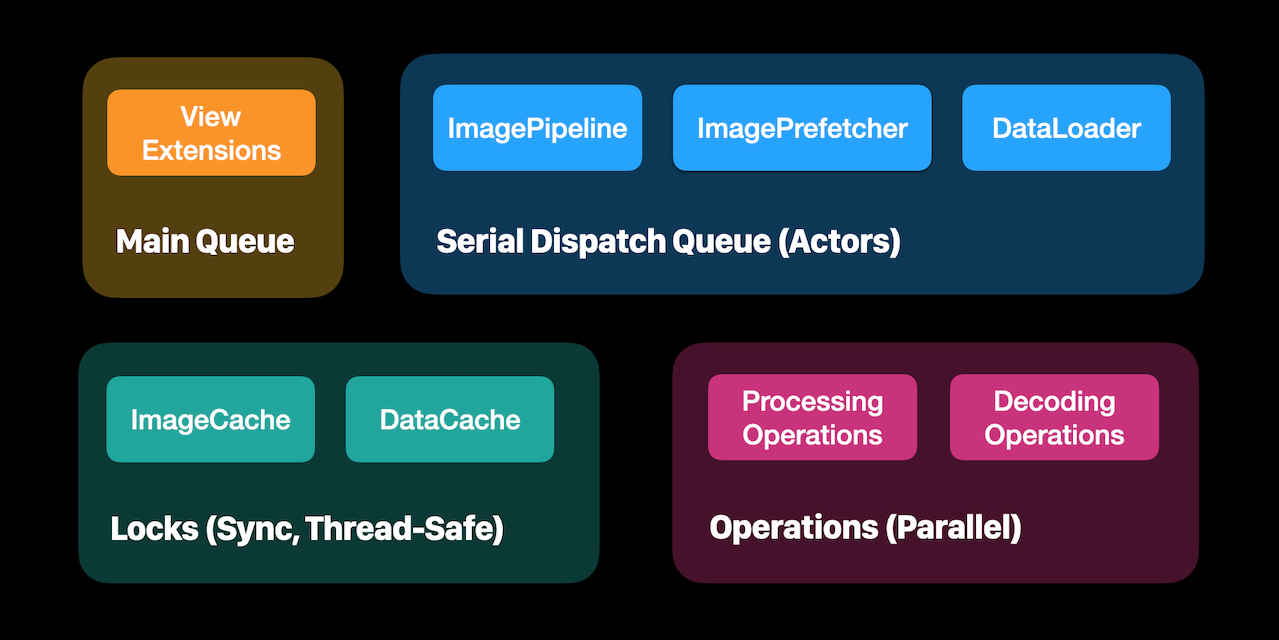
There is a tiny portion of code that is not thread-safe and can only run from the main thread because it updates UI components, be it UIKit or SwiftUI. This code has assertions to catch errors early: assert(Thread.isMainThread). The rest of the code operates in the background and this is what the article covers.
Actor Model #
Actors allow you as a programmer to declare that a bag of state is held within a concurrency domain and then define multiple operations that act upon it. Each actor protects its data through data isolation, ensuring that only a single thread will access that data at a given time, even when many clients are concurrently making requests of the actor.
From SE-0306
The actor model is a pattern. It doesn’t have to be included in the language, but the goal of the Swift team is to add to one of the main Swift strengths: safety via compile-time checks. With the actor model, you will get isolation checks at compile-time along with other safety features.
I’ve been designing classes as actors in Objective-C since GCD was added in iOS 4. I’m designing Swift classes as Actors now. And I can’t wait to start designing them using a formal actor model.
While the formal definition seems a bit complicated, you can simply think of an actor as a class with some private state and an associated serial dispatch queue2. The only way to access the state is to do it on the serial queue. It ensures there are never any data races.
I designed most of the public components in Nuke that have to be thread-safe as actors: ImagePipeline, ImagePrefetcher, DataLoader.
ImagePipeline #
ImagePipeline is the main component you interact with as a user to fetch images. It has to be fast because you often use it during scrolling, and it has to be thread-safe. The pipeline (or most of it in the current iteration) is designed as an actor.
/// Not the actual implementation, just a demonstration
public final class ImagePipeline {
private let queue = DispatchQueue(label: "ImagePipeline", qos: .userInitiated))
/// Private state ...
private var tasks = [ImageTask: TaskSubscription]()
public func loadImage(_ url: URL, completion: @escaping (Image?) -> Void) {
queue.async {
// Access instance properties in a thread-safe manner and act upon them
}
}
}
Now the pipeline is fully thread-safe and does its work in the background reducing contention on the main thread. Why is it important? The pipeline does quite a lot: coalescing, creating, and starting URL requests, which can take about 0.7ms on older devices. Apps can’t always afford it when scrolling a collection view with multiple images per row. Scheduling async work on a DispatchQueue, on the other hand, is relatively fast – maybe a few microseconds. It’s not free but is faster than the work in this case.
ImagePrefetcher #
ImagePrefetcher helps you manage image prefetching per screen and is also an Actor.
/// Not the actual implementation, just a demonstration
public final class ImagePrefetch {
private let pipeline: ImagePipeline
private let queue = DispatchQueue(label: "ImagePrefetch", qos: .userInitiated))
/// Private state...
private let tasks = [URL: ImageTask]()
public func startPrefetching(urls: [URL]) {
queue.async {
for url in urls {
self.tasks[url] = self.pipeline.loadImage(with: url) { [weak self] in
self?.didCompleteTask(url: url)
}
}
}
}
private func didCompleteTask(url: URL) {
queue.async {
self.tasks[url] = nil
}
}
}
Now here is a problem. Let’s say you start prefetching images with 4 URLs. How many queue.async calls can you count?
- 1 made by the prefetcher to access its state in
startPrefetching(urls:) - 4 made by the pipeline to access its state in
loadImage(url:) - 4 made by the prefetcher, one per completion callback
That’s a bit too much. Can we optimize it?
One option is to forget about thread-safety and background execution and synchronize on the main thread. But prefetcher is also used during scrolling. A collection view prefetch API can ask you to start prefetching for 20 or more cells at a time. If sending it to background is faster than executing on the main queue, I would prefer to do it. When 120Hz displays for iPhones drop, you will be happy to get any optimizations you can.
Always measure. Sending work to the background will often be slower than executing it synchronously on the current thread and synchronizing with locks.
To avoid the excessive number of context switches, Nuke synchronizes3 two actors (pipeline and prefetcher) on a single dispatch queue, dropping the number of queue.async calls to just one!
Can you still call this approach an actor model? I think it’s a stretch, but I will let it slide. I definitely won’t be able to implement it this way with just features from SE-0306: Actors, but Global Actors Pitch hints at a solution. One could also think about this as a confirmation that actors synchronization can be too granular.
DataLoader #
I apply a similar optimization to the default data loader (DataLoader). When the pipeline is initialized, it injects the synchronization queue into the data loader. And it gets even more exciting!
This is the initial implementation of the DataLoader:
/// Not the actual implementation, just a demonstration
public final class DataLoader {
public init() {
let queue = OperationQueue()
queue.maxConcurrentOperationCount = 1
session = URLSession(configuration:configuration, delegate: self, delegateQueue: queue)
}
func loadData(for request: URLRequest, completion: @escaping (Data?) -> Void) {
let task = session.dataTask(with: request)
let handler = _Handler(didReceiveData: didReceiveData, completion: completion)
session.delegateQueue.addOperation { // Dispatch #1
self.handlers[task] = handler
}
task.resume()
return task
}
func dataTask(_ dataTask: URLSessionDataTask, didReceive data: Data) {
guard let handler = handlers[dataTask] else {
return
}
handler.didReceiveData(data)
}
/// ...
}
private final class LoadDataTask {
func didReceiveData(_ data: Data) {
pipeline.queue.async { // Dispatch #2
// ...
}
}
}
DataLoader uses a background operation queue as a URLSession delegate queue, which is great because it reduces contention on the main thread. But it is a new private queue – the same problem as with the prefetcher. Here is a trick, OperationQueue allows you to set an underlyingQueue. In the optimized version, DataLoader uses the pipeline’s serial queue as a delegate queue.
extension DataLoader {
func inject(_ queue: DispatchQueue) {
session.delegateQueue.underlyingQueue = queue
}
}
Now the entire system is synchronized on a single serial dispatch queue!
Main Queue? #
If you synchronize on the main queue, the important words are “synchronizing” and “queue”. The queue doesn’t have to be your main queue. Using the main queue does make it easier to avoid UI updates from the background queue, but Thread Sanitizer catches those immediately, so it’s relatively easy to avoid.
There is also a flaw in synchronizing on main. If your subsystems assume they are only called from a single queue, they are not thread-safe. If you accidentally call any of them from the background, you can introduce subtle bugs which are harder to find than simple UI updates from the background, unless you fill your code with assertions. And if your app becomes big enough that it can no longer afford to operate strickly on the main queue, you are going to be up to major rethinking of your components (been there).
If you need thread-safety and mutable state, the actor model is probably your best bet. From the two concurrency models: shared memory and messages passing, I find the latter to be more appealing.
Tasks #
Nuke has an incredible number of performance features: progressive decoding, prioritization, coalescing of tasks, cooperative cancellation, parallel processing, backpressure, prefetching. It forces Nuke to be massively concurrent. The actor model is just part of the solution. To manage individual image requests, it needed a structured approach for managing async tasks.
The solution is Task, which is a part of the internal infrastructure. When you request an image, Nuke creates a dependency tree with multiple tasks. When a similar image request arrives (e.g. the same URL, but different processors), an existing subtree can serve as a dependency of another task.
Nuke supports progressive decoding and task design reflects that. It is inspired by reactive programming, but is optimized for Nuke. Tasks are much simpler and faster than a typical generalized reactive programming implementation. The complete implementation takes just 237 lines.
Will Nuke adopt async/await for its internal infrastructure? Unlikely, as it probably won’t cover all the scenarios I need. But I am considering replacing tasks with Combine when Nuke drops iOS 12 support.
Locks #
Nuke also extensively uses locks (NSLock) for synchronization. ImageCache, DataCache, ResumableData – there are a few components that use them. They all have public synchronous APIs, so they have to be thread-safe.
Locks allow you to protect a critical section of code. You
lock()when the section starts, andunlock()when you are done. Unlike semaphores, unlock has to be sent from the same thread that sent the initial lock messages.
There isn’t much to say about locks. There are easy to use and fast4. I don’t trust any of the performance benchmarks that measure the performance difference between different synchronization instruments. If there even is a measurable difference, it’s irrelevant in the scenarios where I use them.
DataCacheis a bit more complicated than that. It writes data asynchronously and does so in parallel to reads, while reads can also be parallel to each other. It’s a bit experimental, I haven’t tested the full impact of this approach on the performance.
Atomics #
I’m using atomics (OSAtomicIncrement32, OSCompareAndSwap32) in a couple of places in Nuke. For example, in Operation I use CAS to guarantee that the finish() callback is only executed once. But when Thread Sanitizer was introduced it started emitting warnings5.
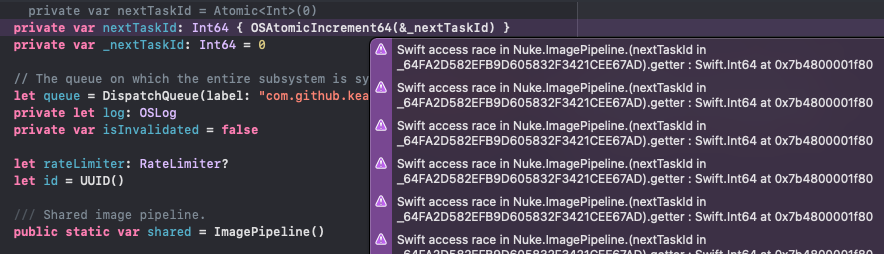
Turns out, & operator doesn’t do what you might think it does. I had to switch to using pointers to continue using atomics.
OperationQueues #
The expensive operations, e.g. decoding, processing, data loading, are modeled using Foundation.Operation. Operation queues are used for parallelism with a limited number of concurrent operations. They are also used for prioritization which is crucial for some user scenarios. There isn’t much else to say about operation queues that haven’t already been said.
Conclusion #
It’s always best to avoid concurrency or mutable state, but sometimes it’s not feasible. To write responsive client-side programs6, you often have to embrace concurrency. There are, of course, kinds of tasks that obviously have to be asynchronous, such as networking. But if you want to use background processing as an optimization, always measure! Performance is about doing less, not more.
Measuring is an art on its own. Modern CPUs with different cache levels and other optimizations make it hard to reasons about performance. But at least make sure to measure in Release mode (with compiler optimizations on) and check that you are getting consistent results. The absolute measurements might not always be accurate, but the relative values will guide you in the right direction. Avoid premature optimization, but also don’t paint yourself into a corner where the only way to improve performance is to rewrite half of the app.
Nuke has many optimizations, some impractical, so don’t just go and copy them. I just finished watching F1 Season 3 (which was phenomenal, by the way). I can’t say that I’m a huge F1 fan, but I appreciate things designed for performance and a bit of competition. I’m not always stopping where a sane person should.
References
- Nuke, an image loading and caching system
- Pulse, a structured logging system
- SE-0306: Actors
-
Or are Xcode blocking the main thread for 20+ seconds at a time when checking run destinations with WiFi deployment enabled. Sorry, Xcode, I didn’t mean to be mean. ↩
-
It appears that the actual implementation in Swift won’t be using dispatch queues. I’m also curious to learn more about a lighter-weight implementation of the actor runtime mentioned in the Swift Evolution proposal that isn’t based on serial
DispatchQueue. ↩ -
The implementation isn’t particularly interesting. It’s just prefetcher calling internal pipeline APIs, which isn’t great as it breaks the actor metaphor. I’m investigating whether I can generalize it (actor to check which queue it’s running on and passing synchronization context between actors?). ↩
-
Especially after the recent-ish performance optimizations, which I can’t find a link for right now. Locks are especially efficient in situations where there isn’t a lot of contention, so they don’t need to go to the kernel level. ↩
-
You can learn more about why these warnings get emitted in the following post. ↩
-
And servers! Modern server-side frameworks, such as SwiftNIO also embraced concurrency and non-blocking I/O. ↩