![]()
Nuke 9 is a culmination of five years of development. The project started soon after Swift release, as a continuation of DFImageManager, an Objective-C image loading framework1. I put a lot of effort and care into each and every iteration of Nuke, but Nuke 9 feels special.
Nuke 9 is packed with improvements across the board: SwiftUI integration, Combine support, new builder API, fantastic new API reference generated using SwiftDoc, completely reworked documentation, support for more image formats, new advanced versions of ImageProcessing and ImageDecoding protocols, and more. However, in this post, I would like to talk about something else.
What makes Nuke truly stand out? The answer is performance. Every feature in Nuke is engineered with performance in mind. The goal of the entire framework is to display images to the user as quickly as possible. There have been a lot of performance-related changes introduced in Nuke over the years, and I would like to give an overview of some them.
Caching #
The primary reason to use an image loading framework is caching. Images tend to take a lot of space. You want to make sure that when you download an image, you don’t have to download it again next time. Nuke offers three caching layers.
L1. Memory Cache #
The processed images are stored in a fast in-memory cache (ImageCache). ImageCache was originally intoduced in Nuke 4.0 to replace NSCache2. It uses LRU (least recently used) replacement algorithm and has a limit of ~20% of available RAM. ImageCache automatically evicts images on memory warnings and removes a portion of its contents when the application enters background mode. You can configure cost, count limits, and time-to-live.
L2. HTTP Disk Cache #
By default, unprocessed image data is stored in native URLCache, which is part of the Foundation URL Loading System. The main feature of URLCache is its support of Cache Control. It allows the server to control caching. Here is an example of an HTTP header with cache control.
HTTP/1.1 200 OK
Cache-Control: public, max-age=3600
Expires: Mon, 26 Jan 2016 17:45:57 GMT
Last-Modified: Mon, 12 Jan 2016 17:45:57 GMT
ETag: "686897696a7c876b7e"
This response is cacheable and it’s going to be fresh for 1 hour. When the response becomes stale, the client validates it by making a conditional request using the If-Modified-Since and/or If-None-Match headers. If the response is still fresh the server returns status code 304 Not Modified to instruct the client to use cached data, or it would return 200 OK with a new data otherwise.
You can learn more about HTTP cache in Image Caching guide.
L3. Aggressive Disk Cache #
If HTTP caching is not your cup of tea, you can use a custom LRU disk cache (DataCache) introduced in Nuke 7.4 for fast and reliable aggressive data caching.
DataCache in Nuke is unique. A typical implementation would perform all the work on a single dispatch queue. DataCache, on the other hand, uses non-blocking writes, and allows reads to be parallel to writes and each other. This significantly improves performance.
If you enable DataCache, then by default, the pipeline will use it to store only the original image data. To store processed images, set dataCacheOptions.storedItems to [.finalImage]. This option is useful if you want to store processed, e.g. downsampled, images or if you want to transcode images to a more efficient format, like HEIF.
To save disk space see
ImageEncoders.ImageIOandImageEncoder.isHEIFPreferredoption for HEIF support.
Caching is crucial for improving performance. Sometimes it even makes sense to pre-populate the caches before the user needs the content.
Prefetching #
Prefetching resources is an effective way to improve the user experience for many apps. Prefetching means downloading data ahead of time in anticipation of its use. For example, you have a grid of images displayed using UICollectionView, and you want to prefetch images just outside of the visible area.
Nuke has ImagePreheater class introduced very early in Nuke 0.2. It can be used for managing the prefetching requests. To start prefetching, call startPreheating(with:) method. When you need an individual image, just start loading them, the pipeline will automatically reuse the existing tasks and add new observers to them instead of starting the new download.
Prefetching takes up the user’s data and puts pressure on CPU and memory.
To reduce the CPU and memory usage, you have an option to choose only the disk cache as a prefetching destination (introduced in Nuke 7.4):
// The preheater with `.diskCache` destination will skip image data decoding
// entirely to reduce CPU and memory usage. It will still load the image data
// and store it in disk caches to be used later.
let preheater = ImagePreheater(destination: .diskCache)
On iOS, you can use prefetching APIs in combination with
ImagePreheaterto automate the process.
ImagePreheater class itself is fairly simple. The magic happens thanks to the coalescing mechanism built into ImagePipeline.
Coalescing #
Coalescing is probably the most powerful and complex Nuke feature. To get it right, it required a complete redesign of the ImagePipeline in Nuke 8.0. Now what is coalescing?
Thanks to coalescing, the pipeline avoids doing any duplicated work when loading images. Let’s take the following two requests as an example.
let url = URL(string: "http://example.com/image")
pipeline.loadImage(with: ImageRequest(url: url, processors: [
ImageProcessors.Resize(size: CGSize(width: 44, height: 44)),
ImageProcessors.GaussianBlur(radius: 8)
]))
pipeline.loadImage(with: ImageRequest(url: url, processors: [
ImageProcessors.Resize(size: CGSize(width: 44, height: 44))
]))
Nuke will load the data only once, resize the image once and blur it also only once. There is no duplicated work done. Nuke reuses each of the individual stages (or tasks) of the pipeline. Each time it sees duplicated work, it registers the request with an existing task. The work only gets cancelled when all the registered requests are, and the priority is based on the highest priority of the registered requests.
{kind=link}
How is coalescing implemented? Initially, the pipeline was implemented in an imperative way: load image data, decode it, decompress and process the image, etc. This is how most frameworks implement it. In Nuke 8.0, the order is reversed. When you request an image, the pipeline creates a task which fetches the processed image, the task asks for a decoded image, which in turn asks for image data, etc. This way the pipeline declaratively creates a dependency graph between tasks. All of the tasks are added to respective reuse pools.
Taskis an abstraction introduced in Nuke 7.0 which allows multiple observers to subscribe to the same work. However, it’s not all that simple. Nuke also supports progressive decoding. To accommodate it,Tasktakes inspiration from reactive programming, dispatching events to multiple observers as they arrive or the work is completed.Taskis 186 lines of highly tested code which get you 90% there.
Progressive Decoding #
Nuke 7.0 also added support for progressive JPEG. It’s very easy to enable progressive decoding, and with Nuke 9.0 you can now even store progressive previews in the memory cache.
let pipeline = ImagePipeline {
$0.isProgressiveDecodingEnabled = true
// If `true`, the pipeline will store all of the progressively generated previews
// in the memory cache. All of the previews have `isPreview` flag set to `true`.
$0.isStoringPreviewsInMemoryCache = true
}
And that’s it, the pipeline will automatically do the right thing and deliver the progressive scans via progress closure as they arrive. Instead of describing its advantages, it’s best to just show it.
Please keep in mind that it’s not just progressive JPEG or nothing. You could optimize the baseline JPEG by loading a thumbnails and displaying them first. It easy to do that either using RxNuke or ImagePublisher.
Getting progressive decoding right was quite a challenge. It required a complete redesign of the ImagePipeline in Nuke 7.0. For example, one of the important details to get right was backpressure – what happens if the data is downloaded faster than the pipeline processes it.
Rate Limiting #
Nuke.loadImage(with:into:) family of methods supports cell reuse. Before loading a new image, the target view is prepared for reuse by canceling any outstanding requests and removing a previously displayed image. It can happen very quickly if the user quickly scrolls a scroll view. It was a problem, as it would sometimes trash the underlying data loading system (Foundation.URLSession) to the point that it would crash. To mitigate this issue, Nuke 4.0 introduces3 a RateLimiter class.
RateLimiter limits the rate at which URLSessionTasks are created. RateLimiter uses a classic token bucket algorithm. The implementation supports quick bursts of requests which can be executed without any delays when “the bucket is full”. This is important to make sure RateLimiter only kicks in when needed, but when the user just opens the screen, all of the requests are fired immediately.
Resumable Downloads #
Canceling downloads sounds wasteful, what if the significant portion of the data was already downloaded? Starting with Nuke 7.0 this is not a concern thanks to resumable downloads. If the data task is terminated (either because of a failure or a cancellation) and the image was partially loaded, the next load will resume where it was left off. In many use cases, resumable downloads are a massive improvement to user experience, especially on the mobile internet.
Resumable downloads require server support for HTTP Range Requests. Nuke supports both validators (
ETagandLast-Modified).
Request Priority #
Nuke is fully asynchronous and performs well under stress. ImagePipeline distributed its work on operation queues dedicated to a specific type of work, such as processing, decoding. Each queue limits the number of concurrent tasks, respects the request priorities, and cancels the work as soon as possible.
Starting with Nuke 6.1, the framework started taking advantage of the priority of Foundation.Operation. You could now configure an image request with 5 available priority options ranging from .veryLow to .veryHigh. You can even change the priority dynamically after the request is already started. Now, why is this important?
Here is an idea. Let’s say you have a grid of images. When the user taps on an image, you open it fullscreen. Typically, you would keep the requests in the grid running. However, now you can reduce the priority of the requests in the grid to make sure they don’t interfere with the fullscreen experience.
Main Thread Performance #
Nuke is packed with performance optimizations. There a benchmark that I run periodically to see how it compares with other frameworks in regards to main thread performance.

How does Nuke achieve its performance? It’s not just one optimization, it’s a whole range of optimizations across the board. I’ll give just a few examples.
- CoW. The primary type in Nuke is
ImageRequest. It has multiple options, so the struct is quite large. To make sure that passing it around is as efficient as possible,ImageRequestemploys a Copy-on-Write technique. This, and many other optimizations, was introduced in Nuke 4.1 which was the first purely performance-focused release. - ImageRequest.CacheKey. A typical framework would use strings to uniquely identify a request. But string manipulations are expensive, this is why in Nuke, there is a special internal type,
ImageRequest.CacheKey, which allows for efficient equality checks for image requests with no string attached. - Thread Confinement. Nuke knows that
Nuke.loadImage()family of methods only usesImageTaskon the main thread. It means that it can skip some synchronizations.
These are just some examples of the optimization techniques used in Nuke. There are many more. Every new feature in Nuke is designed with performance in mind to make sure there are no performance regressions ever.
Nuke 9.3.0 also introduces some similar performance improvements to the work that Nuke does in the background. If you measure just Nuke code, it takes about 0.004 ms (4 microseconds) on the main thread per request and about 0.03 ms (30 microseconds) overall, as measured on iPhone 11 Pro. Virtually unnoticeable.
Signposts #
With all of these features in place, it can be quite challenging to understand the performance characteristics of the system. Fortunately, with os_signpost integration added in Nuke 8.0, it’s easier than ever. Signposts allow you to have visibility into the pipeline. With Signposts Instrument, you can see which stages take more time.
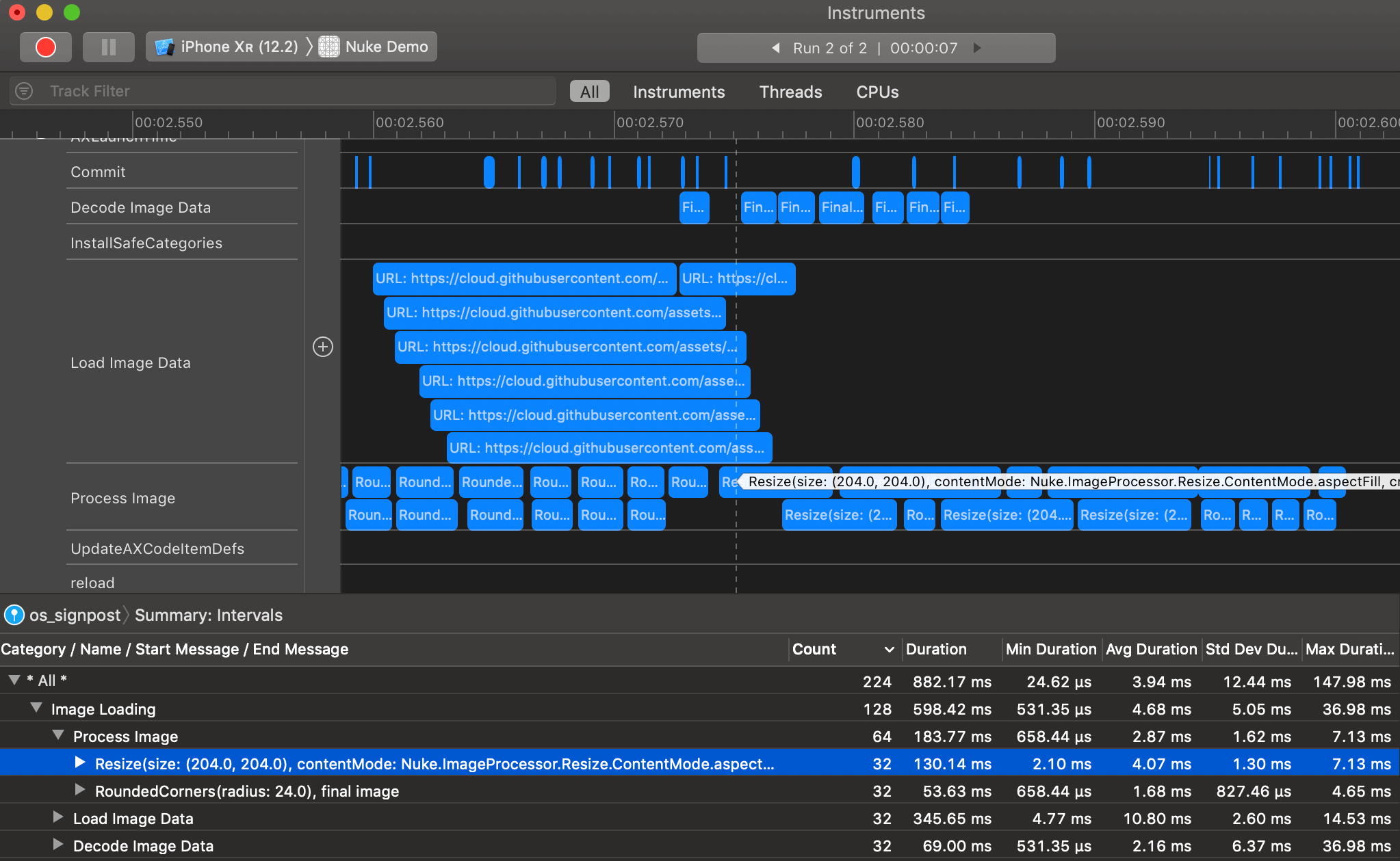
For more information see WWDC 2018: Measuring Performance Using Logging which explains
os_signpostin a great detail.
Final Thoughts #
I’m proud of what I was able to achieve with Nuke. It is used by thousands of apps and has been widely recognized on GitHub. There are two tutorials on Nuke on raywenderlich.com. GitHub named Nuke 7 one of the best releases in May 2018. Nuke was on the list of top trending frameworks on GitHub many times.
Over the years Nuke has grown from a tiny 500 lines of code project to a complete and mature library which so many people rely on. In the recent master, only unit tests take 5000 lines of code. There is so much care and details which went into each iteration of Nuke. With Nuke 9, it finally reaches its full potential.
-
DFImageManager was one of the only SDWebImage competitors at the time. It was the first image loading framework to use NSURLSession with HTTP/2 support, to feature AFNetworking and FLAnimatedImage integration, and have intelligent prefetching/coalescing support. ↩
-
There are a few reasons why
NSCachewas replaced. The caching algorithm forNSCacheis not documented and there was evidence that it wasn’t LRU.ImageCachealso has more control over caching, add support for features like Time-to-Live. Another problematic aspect ofNSCacheis that keys must be objects which isn’t optimal. ↩ -
Nuke 4.0 also introduced some questionable new APIs. For example, it included a public
Promiseimplementation in the framework and replaced the closure based APIs with promises. I don’t remember exactly why I made this change, but just a couple of weeks later it was clear it was a mistake. Nuke 4.0 also went way too far on abstractions, protocols, and single responsibility principle, making the code harder, not easier to reason about. It took three major releases, Nuke 5.0, 6.0, and 7.0 to gradually undo the damage that Nuke 4.0 done. Fortunately, not a lot of people were using Nuke at the time. ↩